日志检索器追踪
笔记
如果您未以正确的格式记录检索器(retriever)跟踪信息,系统不会发生任何错误,数据仍会被记录。但该数据将无法以专用于检索器步骤的方式进行渲染。
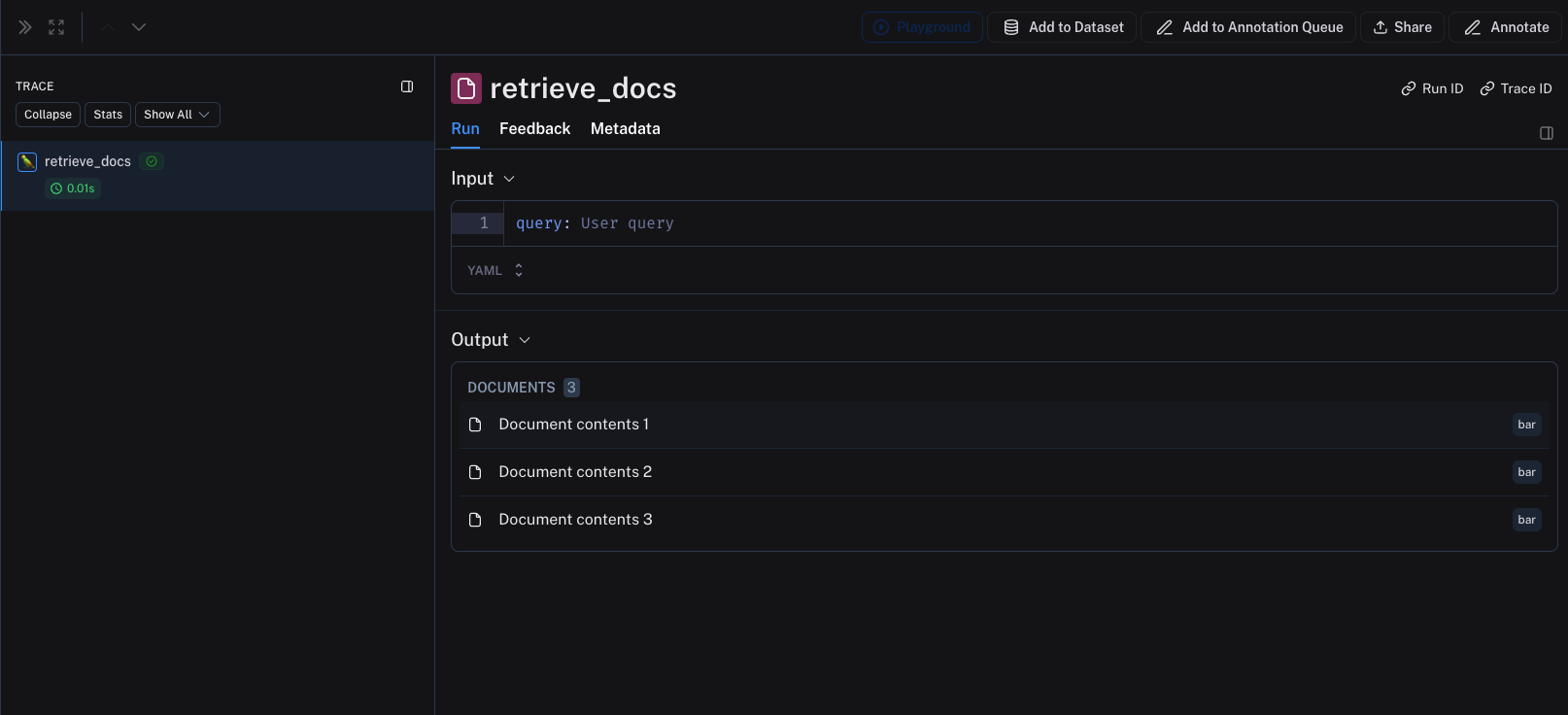
许多大语言模型(LLM)应用需要从向量数据库、知识图谱或其他类型的索引中检索文档。检索器追踪(Retriever traces)是一种记录检索器所获取文档的方法。 LangSmith 为追踪中的检索步骤提供了专门的可视化渲染,以便更轻松地理解与诊断检索问题。要使检索步骤得以正确渲染,需完成几个简单的步骤。
- 使用
run_type="retriever"为检索器步骤添加注释。 - 从检索器步骤返回一个 Python 字典列表或 TypeScript 对象列表。每个字典应包含以下键:
page_content:文档的文本内容。type:此处应始终为“Document”。metadata: 一个包含文档元数据的 Python 字典或 TypeScript 对象。该元数据将在追踪信息中显示。
以下代码片段展示了如何在 Python 和 TypeScript 中记录检索步骤。
- Python
- TypeScript
from langsmith import traceable
def _convert_docs(results):
return [
{
"page_content": r,
"type": "Document",
"metadata": {"foo": "bar"}
}
for r in results
]
@traceable(run_type="retriever")
def retrieve_docs(query):
# Foo retriever returning hardcoded dummy documents.
# In production, this could be a real vector datatabase or other document index.
contents = ["Document contents 1", "Document contents 2", "Document contents 3"]
return _convert_docs(contents)
retrieve_docs("User query")
import { traceable } from "langsmith/traceable";
interface Document {
page_content: string;
type: string;
metadata: { foo: string };
}
function convertDocs(results: string[]): Document[] {
return results.map((r) => ({
page_content: r,
type: "Document",
metadata: { foo: "bar" }
}));
}
const retrieveDocs = traceable(
(query: string): Document[] => {
// Foo retriever returning hardcoded dummy documents.
// In production, this could be a real vector database or other document index.
const contents = ["Document contents 1", "Document contents 2", "Document contents 3"];
return convertDocs(contents);
},
{ name: "retrieveDocs", run_type: "retriever" } // Configuration for traceable
);
await retrieveDocs("User query");
以下图片展示了检索器(retriever)步骤在追踪(trace)中的渲染效果。每个文档均显示其内容及对应的元数据。